目次

これまで世界中の研究者は、たった1つの「標準の地図(GRCh38)」を基準にしてヒトのDNAを読み解いてきました。ところがこの地図は、その約7割が特定のひとりに由来する不完全なもので、集団ごとの多様性を十分に表せませんでした。この限界を乗り越えるために作られているのが、世界中の多様な人々のゲノムを1つに束ねた新しい標準リファレンス「ヒトパンゲノム(Human Pangenome)」です。本記事では、その仕組みから、脊髄性筋萎縮症(SMA)やリポタンパク質(a)といった実際の遺伝子診断への影響までを、遺伝専門医の視点でやさしく解説します。
Q. ヒトパンゲノムとは何ですか?まず結論だけ知りたいです
A. ヒトパンゲノムとは、1本の直線ではなく「分かれ道」を持つグラフの形で、世界中の多様な人々のゲノムを1つにまとめた新しい標準リファレンス(基準配列)です。従来の1人中心の地図では読み飛ばされていた個人差や構造の違いを保持できるため、参照バイアスが減り、複雑な遺伝子領域の読み取り精度が上がります。すでにSMAの保因者検査やLp(a)関連の心血管リスク評価など、具体的な診断の場面で役立ち始めています。
- ➤基本の考え方 → 「1つの直線の地図」から「多様な道を含むグラフの地図」へ
- ➤解析精度の向上 → 小さな変異の発見エラーが34%減少、構造変異の検出が約2倍に
- ➤HPRCの歩み → 47人(2023年)から350人超の完全ゲノム(2026年予定)へ拡大
- ➤臨床での恩恵 → SMA(SMN1/SMN2)やLp(a)など、これまで難しかった領域の診断が前進
- ➤公平性への配慮 → FAIR原則とCARE原則を両立させ、多様な集団に恩恵を届ける設計
1. ヒトパンゲノムとは?「1本の地図」から「分かれ道のある地図」へ
私たちのからだの設計図であるDNAを読み解くとき、研究者や医師は必ず「基準となる配列(リファレンスゲノム)」と照らし合わせて、その人のDNAがどこでどう違うのかを判定します。この20年あまり、その世界共通の基準として使われてきたのがヒトゲノムの標準配列「GRCh38」です。共通のものさしがあることで、世界中のデータを比較・共有でき、医学は大きく進歩しました[1]。
しかし、この標準配列には根本的な弱点があります。GRCh38は20人以上のDNAをつなぎ合わせたモザイク状の配列ですが、その全体の約70%が、たったひとりの人物に由来しています[2]。しかも一本の直線としてつながっているため、世界中の多様な集団が持つ「配列の形そのものの違い」を表現しきれません。ある集団に特有の並び方をしたDNAを持つ人を検査すると、その配列は標準の地図にうまく当てはまらず、読み飛ばされてしまいます。これが「参照バイアス」と呼ばれる、解析のゆがみの原因です。
この課題を解決するために生まれたのが「ヒトパンゲノム」です。「Pan」はギリシャ語で「すべてを含む」を意味します。世界中の多様な祖先を持つ人々の高精度なゲノムを、1本の直線ではなく「分かれ道(分岐パス)を持つグラフ構造」として1つにまとめたものが、ヒトパンゲノムの正体です。米国国立衛生研究所(NIH)傘下の国立ヒトゲノム研究所(NHGRI)の資金支援を受けた国際コンソーシアム「ヒトパンゲノムリファレンスコンソーシアム(HPRC)」が、その構築を主導しています[2]。
「グラフ」と聞くと難しく感じるかもしれませんが、イメージは電車の路線図に近いものです。基本となる1本の線路(共通の配列)があり、人によって使う「分岐した線路」が違う、と考えてください。ある集団ではよく使われる分岐が、別の集団ではあまり使われない——そうした個人差や集団差を、あらかじめ地図の中に「別ルート」として描き込んでおくのがパンゲノムです。生成されたデータはオープンな資源として広く公開され、Googleの研究者などもオープンソースの解析ツールの開発に参画しています。誰もが使える共通基盤として整備されている点も、この取り組みの大きな特徴です。
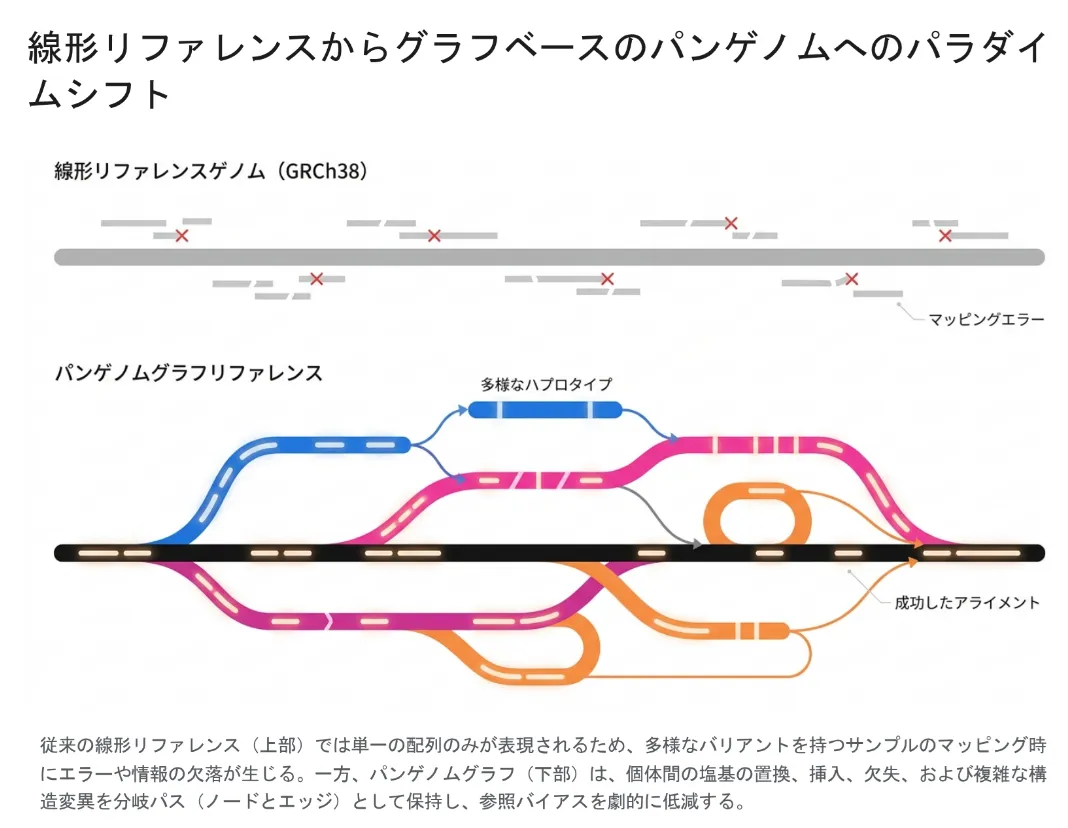
従来の線形リファレンス(上)では、形の違う配列は基準に当てはまらず読み飛ばされます。一方、パンゲノムグラフ(下)では多様なハプロタイプが「分かれ道」として保持されるため、個人差を持つ配列もきちんと位置づけられます。
💡 用語解説:リファレンスゲノムと参照バイアス
リファレンスゲノムとは、DNA解析の「基準となる地図」です。検査で読み取った短いDNA断片(リード)を、この地図のどの位置に当てはまるか照合することで、変異を見つけます。ところが基準の地図が1人中心で偏っていると、地図と形が大きく違う人のリードは当てはめに失敗します。この現象を参照バイアス(Reference bias)と呼び、変異の見落としや解析結果のゆがみにつながります。パンゲノムは、多様な道をあらかじめ地図に描いておくことで、このバイアスを大きく減らします。
2. なぜヒトパンゲノムが必要なのか
「たった1人分に偏った地図の何が問題なのか」を、もう少し具体的に見ていきます。人と人のゲノムは平均すると99%以上が共通していますが、残るわずかな違いこそが、体質や病気のなりやすさ、薬の効き方を左右します。この違いには、1文字だけ入れ替わる一塩基バリアント(SNV)のような小さなものから、DNAの大きな塊が入れ替わったり増えたりする構造変異(SV)まで、さまざまな種類があります。
とりわけ問題になるのが構造変異です。ある集団に固有の大きな並び替えを持つ人を、1人中心の直線の地図で解析すると、その領域はまるごと「地図に無い場所」になってしまい、正確に読み取れません。実際、HPRCが2023年に発表した最初のドラフトパンゲノムは、47人・94ハプロタイプ(父由来・母由来の2セット)から構成され、各ゲノムの99%以上を99%以上の精度でカバーしましたが、この過程で従来のGRCh38には無かった約1億1900万塩基対もの多型的な配列が新たに見つかりました[3]。これは、1人中心の地図がいかに多くの情報を取りこぼしていたかを物語ります。
具体的に想像してみましょう。ある人が、標準の地図には無い「1万文字の挿入」を持っていたとします。この人の検査データを1本の直線の地図に当てはめようとすると、その1万文字ぶんの断片は「行き場所」が地図上に存在しないため、うまく貼り付けられずに捨てられてしまいます。結果として、本来そこにあるはずの情報が「無い」ことになってしまうのです。パンゲノムでは、この挿入があらかじめ「分かれ道」として地図に用意されているため、断片はきちんと正しい場所に収まります。これが、構造変異の検出がパンゲノムで大きく改善する理由です。ドラフトパンゲノムでは、GRCh38に対して1000を超える遺伝子の重複も新たに書き加えられました[3]。
💡 用語解説:ハプロタイプと二倍体
私たちは父と母から1セットずつ、合計2セットのゲノムを受け継いでいます(二倍体)。この片方ずつの並びをハプロタイプと呼びます。従来の地図は父由来・母由来を混ぜた1本にまとめていましたが、パンゲノムでは父由来・母由来をきちんと分けて(フェージングして)保持します。47人分なら94ハプロタイプ、というのはこのためです。両親由来を分けることで、どちらの染色体にどの変異があるのかまで正確に読み取れるようになります。
参照バイアスは、病気と遺伝子の関連を大人数で調べるゲノムワイド関連解析(GWAS)や、遺伝子がどれだけ働いているかを調べる発現解析にも影響します。特定の集団のデータほど当てはめに失敗しやすいため、地図が偏っていると、その集団に関する医学的知見が構造的に不足してしまいます。ヒトパンゲノムが目指すのは、単なる精度向上だけでなく、どの集団の人も公平に、正確に解析できる基盤を作ることなのです。
3. HPRCの歩み:47人から350人超の「完全ゲノム」へ
ヒトパンゲノムは一度に完成したわけではなく、シーケンシング技術とアルゴリズムの進歩に合わせて、段階的に質と量を高めています。HPRCが公開している計画では、大きく3つの節目があります[4]。
ヒトパンゲノムの拡大:収録ハプロタイプ数の推移
父由来・母由来を分けた配列(ハプロタイプ)の本数。多いほど多様性を反映します
Release 1
2023年5月 / 47人
Release 2
2025年5月 / 200人超
Release 3(予定)
2026年夏 / 350人超
2023年5月に学術誌『Nature』などで発表された「Release 1」は、世界初のヒトパンゲノムリファレンスのドラフトでした。1000人ゲノムプロジェクトから選ばれた、遺伝的・地理的に多様な47人から得られた二倍体ゲノムアセンブリ(計94ハプロタイプ)で構成されています[3]。続く2025年5月の「Release 2」では規模がほぼ5倍に拡大し、200人以上(400ハプロタイプ超)へと成長しました。同時にアルゴリズムも進化し、塩基レベルの研磨(ポリッシング)工程が加わったことで、細かな読み取り誤りが半分以下に減っています[4]。
そして2026年夏に向けて計画されている「Release 3」は、350以上のアセンブリ(700ハプロタイプ超)から構成され、各染色体の両方が端から端まで途切れなく組み上がった「テロメアからテロメアまで(T2T)」の実質的に完全なゲノム群になる見込みです[4]。米国主導のHPRCだけでなく、国際的な連携(国際ヒトパンゲノムプロジェクト)を通じて、地球規模の多様性を反映する共通インフラづくりが進められています。
この国際連携には、HPRC単独ではなく、ヒトゲノム構造変異コンソーシアム(HGSVC)や各国のパートナーが加わっています。目的は、特定の国や地域のデータだけに偏らない、真に地球規模の基盤を作ることです。生成されたゲノムやアノテーション(遺伝子の位置情報など)は、専用のデータ探索ツールや公共のデータベースを通じて、制限なく公開されています。研究者が自由に使える形でデータが整備されているからこそ、世界中で解析ツールの改良が進み、パンゲノムの価値がさらに高まる——そういう好循環が生まれています。
💡 用語解説:T2T(テロメアからテロメアまで)
染色体の端にある構造をサブテロメア、中央付近のくびれをセントロメアと呼びます。これらは同じ配列がくり返す「読みにくい領域」で、長らくゲノムの空白地帯でした。T2T(Telomere-to-Telomere)とは、この端から端までを1文字も欠かさずつなぎ切った、文字どおり完全なアセンブリを指します。長い配列を一気に読む技術の進歩により、これまでブラックボックスだった領域まで解読できるようになりました。
4. どうやって作るのか:ロングリードとT2Tアセンブリ
🔍 関連記事:ロングリードシーケンス/ナノポアシーケンサー/ショートリードシーケンサー
端から端まで完全なゲノムを組み上げるには、DNAをできるだけ長く、正確に読む技術が欠かせません。HPRCは1つの技術に頼るのではなく、性質の異なる複数の最先端技術を組み合わせて、精度と完全性を両立させています。中心となるのは、次の3つのデータです。
1つ目は、非常に精度の高いロングリードを提供するPacBio HiFiです。約2万塩基という長い断片を高精度で読むため、アセンブリ(組み立て)の骨格となります。2つ目は、ナノポアシーケンサー(Oxford Nanopore)による超長鎖リードで、10万塩基を超える長さを活かして、セントロメアのようなくり返しの多い領域を橋渡しし、端から端までをつなぎ合わせます。3つ目はHi-Cという手法で、染色体の立体構造の情報を使って、父由来・母由来のハプロタイプを確実に分離します。従来のショートリードだけでは届かなかった領域に、これらの長い読みが光を当てているのです。
この3つの技術には、それぞれ役割分担があります。標準的な「アセンブリレシピ」では、PacBio HiFiを約60倍、ナノポアの超長鎖を約30倍、Hi-Cを約30倍という高い深さ(カバレッジ)で読むことが目安とされています。HiFiが「正確さ」を、ナノポアが「長さによるつながり」を、Hi-Cが「父由来・母由来の仕分け」を担当し、互いの弱点を補い合うわけです。とりわけ、同じ配列が延々とくり返すセントロメアや、よく似た配列が重複した領域(セグメンタル重複)は、短い断片では絶対に橋渡しできません。10万文字を超える超長鎖リードがあってはじめて、これらの難所を一気にまたいでつなぐことができます。
💡 用語解説:ロングリードとショートリード
ショートリードは、DNAを100〜300文字ほどの短い断片に分けて大量に読む方式です。安価で正確ですが、断片が短いため、同じ配列がくり返す領域では「どこから来た断片か」を判別できません。一方ロングリードは、1万〜10万文字以上をひとつながりで読む方式です。長いぶんくり返し領域もまたいで読めるため、パズルのピースが大きくなり、複雑な場所も正確に組み上げられます。パンゲノムの完全性は、このロングリード技術の進歩に支えられています。
読み取ったデータをつなぎ合わせて1人分の完全なゲノムを組み立てる作業を「アセンブリ」と呼びます。HPRCの標準となっているのが「Verkko」というパイプラインです(フィンランド語で「網・グラフ」の意)。これは、PacBio HiFiの高精度リードでグラフの骨格を作り、そこにナノポアの超長鎖リードを統合して、もつれをほどきながら端から端までつなぎます。ヒト標準検体を用いた検証では、46本の染色体のうち20本が途切れなく、99.9997%という極めて高い精度でT2Tレベルに組み上がりました[5]。さらに近年は、フェージング情報を使って本物の変異と読み取り誤りを見分ける「Hifiasm」というアルゴリズムも急速に進化し、標準的なナノポアのデータだけからでもT2Tレベルの組み立てが可能になっています[6]。現在のHPRCのパイプラインでは、両者を組み合わせて品質を高めています。

5. 解析の革新:グラフに当てはめると何が変わるのか
完成したパンゲノムグラフを、実際の検査データの解析に使うための「橋渡し役」となるのが、vg giraffe(ブイジー・ジラフ)と呼ばれるツールです。従来のツールは1本の直線に断片を当てはめていましたが、vg giraffeは、多様な道があらかじめ描かれたグラフに対して高速に当てはめを行います。あらかじめ「よくある個人差」が地図に組み込まれているため、無理な計算をせずに正確な位置を見つけられるのが特長です。
もう少し仕組みを説明します。従来の方法は、断片と地図の間に挿入や欠失があるたびに、重い計算をして無理やり位置合わせをしていました。vg giraffeは、よくある個人差がすでに「分かれ道」としてグラフに埋め込まれているため、その道をたどるだけで済み、重い計算の回数を最小限に抑えられます。しかも、線形の地図に当てはめるのと同じくらい高速に動くため、大量の検体を扱う臨床規模の解析にも耐えられる設計になっています。速さと正確さを両立している点が、この仕組みが注目される理由です。
この効果は、数字にもはっきり表れています。ドラフトパンゲノムを使ってショートリードのデータを解析すると、従来のGRCh38ベースの方法に比べて、小さな変異(SNV・インデル)の発見エラーが34%減少し、1ハプロタイプあたりに検出される構造変異の数が104%(約2倍)に増加しました[3][7]。見落としていた変異が見つかり、しかも間違いが減るという、精度の面で大きな前進です。
恩恵は変異検出だけにとどまりません。父由来・母由来のどちらに変異があるかを踏まえた「アレル特異的」な発現解析の信頼性が高まり、これまで捨てられていたデータが救い上げられることで、エピジェネティクス(DNAメチル化など)の解析範囲も広がっています。実際、パンゲノムやT2T配列を用いると、解析できるCpGサイトの数がGRCh38と比べて数%規模で増えることが報告されています[8]。地図が豊かになることで、DNAの「配列」だけでなく「使われ方」の情報まで、より正確に読み取れるようになっているのです。
エピゲノム解析でも同様の恩恵があります。従来のGRCh38ではうまく当てはまらずに捨てられていた断片が救い上げられることで、ChIP-seqやATAC-seqといったクロマチン解析でも、これまで見えなかった特徴が新たに見つかっています。読み取れるデータが増えるほど、遺伝子がいつ・どこで・どのくらい働くのかという「制御の地図」も精密になります。パンゲノムは、DNAの塩基配列という「静的な情報」だけでなく、その使われ方という「動的な情報」の解像度まで押し上げているのです。
💡 用語解説:構造変異(SV)
構造変異(Structural Variant, SV)とは、DNAの比較的大きな塊(おおむね50文字以上)が、欠けたり、増えたり、向きが逆になったり、別の場所へ移ったりする変化のことです。1文字だけの違いに比べてゲノムへの影響が大きく、病気と関わることも少なくありません。しかし塊が大きいぶん、短い断片を直線の地図に当てはめる従来の方法では見つけにくい変異でした。パンゲノムは、この構造変異の検出をとりわけ得意としています。
6. 臨床への応用:SMA・Lp(a)・HLAという難所
🔍 関連記事:脊髄性筋萎縮症(SMA)/SMN1遺伝子/リポタンパク質
パンゲノムの真価は、これまで「読みにくい難所」だった医学的に重要な遺伝子領域を、正確に解像できる点にあります。ここでは代表的な3つの例を紹介します。
脊髄性筋萎縮症(SMA):そっくりな2つの遺伝子を見分ける
脊髄性筋萎縮症(SMA)は、運動神経が変性して進行性の筋力低下を起こす常染色体潜性(劣性)遺伝の重い病気で、およそ出生6,000〜10,000人に1人の割合でみられます。主な原因は、第5染色体にあるSMN1遺伝子の欠失や変異です[10]。ところがこの領域には、SMN1とほとんど同じ配列を持つ「SMN2」という兄弟のような遺伝子が隣り合って存在します。両者の機能的な違いは、ある1文字のスプライシング(配列のつなぎ合わせ)に関わる差にほぼ集約されるため、短い断片を読む従来の方法では、両者を正確に区別することが極めて困難でした。
もう少しくわしく見ると、SMN2はエクソン7という部分の1文字の違いのために、つなぎ合わせ(スプライシング)の際にこの部分が抜け落ちやすく、多くが不安定で短いタンパク質になってしまいます。そのため、SMN1が欠けているとSMN2があっても機能を十分に代われず、病気が起こります。ただしSMN2のコピー数が多いほど症状が軽くなる傾向があり、SMN2が「症状を和らげる調整役」として働きます。つまり、SMN1が何コピーあるか、SMN2が何コピーあるかを正確に数えることが、診断だけでなく重症度の予測にも直結するのです。そっくりな2つの遺伝子を1文字単位で見分けるこの作業こそ、パンゲノムと長い配列を読む技術が最も力を発揮する場面です。
T2Tアセンブリや長い配列を活かしたパンゲノム的アプローチにより、この領域の解像度は飛躍的に向上しました。単純な欠失だけでなく、SMA全体の約5%を占めるとされる非欠失型(複合ヘテロ接合)の変異まで捉えられるようになっています[10]。さらに、SMN1からSMN2への遺伝子変換の切れ目(ブレイクポイント)が、SMA患者のハプロタイプの約45%に存在することも明らかになり、治療薬への反応の予測や、より精密な遺伝カウンセリングの土台が築かれつつあります[11]。
💡 用語解説:保因者スクリーニング
SMAのような常染色体潜性遺伝の病気は、ご本人は健康でも、原因となる変異を1つだけ持つ「保因者」であることがあります。ご夫婦がともに同じ病気の保因者だった場合、お子さんに病気が現れる可能性が生じます。それを妊娠前・妊娠中に調べるのが保因者スクリーニングです。当院では女性向けの拡大保因者検査や男性向けの拡大型保因者検査を行っています。SMN1/SMN2を正確に見分ける技術の進歩は、こうした検査の精度向上に直結します。
リポタンパク質(a):くり返しの数が心血管リスクを左右する
血液中のリポタンパク質(a)(Lp(a))が高いことは、冠動脈疾患の強い独立した危険因子です。この量は、LPA遺伝子の中にある「KIV-2」という部分が、何回くり返しているか(コピー数)に大きく左右されます。KIV-2のくり返し回数は、人によって1回から40回以上まで大きく変動するため、1本の直線の地図ではこの多様性を捉えきれませんでした[12]。
KIV-2の1コピーは約5,500文字の大きさを持ち、それが何十回もくり返すため、全体では非常に長く、しかも一つひとつがよく似ています。短い断片を読む方法では「今読んでいる断片が何番目のくり返しか」を判別できず、コピー数を正確に数えられませんでした。パンゲノム的なアプローチでは、集団によって10〜40%という高い頻度でみられる特定の変異など、くり返し領域の内部に隠れていた多様性まで見えてきています[12]。心血管リスクの評価を、より個人に即した形で行える道が開かれつつあります。
HPRCのハプロタイプ解決済みアセンブリを活かしたパンゲノム的アプローチにより、このくり返し領域に潜む予想外の多様性が次々と見つかっています。くり返しのコピー数(CNV)とLp(a)の量を正確に対応づけられるようになれば、心血管疾患リスクの遺伝的な層別化がより精密になります。これは、大人の予防医療にも関わる重要な進歩です。
HLA/MHC領域とその先へ
第6染色体にあるHLA(ヒト白血球抗原)をコードするMHC領域は、免疫や自己免疫疾患、移植医療で極めて重要ですが、ヒトゲノムの中で最も多型性が高く、正確な判定が難しい難所でした。パンゲノムグラフを使うと、この複雑なハプロタイプ構造を保ったまま解析でき、より高い精度でのタイピングが可能になっています[9]。さらに、初の完全ヒトゲノムやパンゲノムの解析により、従来の地図との間に新たに67もの大規模な「不一致領域」が見つかるなど、これまで見えていなかった構造の違いが次々と明らかになっています[13]。こうした領域には、免疫細胞の分化に関わる遺伝子群なども含まれており、疾患メカニズムの理解を深めています。
たとえば、新たに見つかった不一致領域の1つにあるKLRCという遺伝子群の解析では、ある欠失によってヒトの約20%でKLRC2という遺伝子が失われ、ナチュラルキラー(NK)細胞の分化に影響していることが分かりました[13]。従来の地図には座標そのものが存在しなかったため、これまで完全に見過ごされてきた違いです。パンゲノムが「暗い場所」を照らすことで、免疫や進化に関わる新しい発見が次々と生まれています。
7. 遺伝子診断・遺伝カウンセリングとの接続
ここまで見てきたように、ヒトパンゲノムは「基礎研究の話」にとどまるものではありません。DNA解析の基準そのものが精密になることは、実際の遺伝子診断の質に直接つながります。たとえば、全ゲノム解析(WGS)や次世代シーケンサー(NGS)を使った検査で、これまで区別が難しかったSMN1/SMN2のような領域が正確に読めるようになれば、SMAのNGSパネル検査や保因者スクリーニングの信頼性が高まります。
パンゲノムがもたらす精度向上は、大きく分けて3つの場面で遺伝診療に関わります。第一に、保因者スクリーニングや出生前診断の精度です。読みにくい領域が正確に読めるほど、結果の確からしさが増します。第二に、遺伝形式の解釈です。父由来・母由来のどちらに変異があるかまで分かることで、リスクの説明がより正確になります。第三に、遺伝カウンセリングの質です。曖昧だった領域が明確になれば、ご家族へより誠実な情報提供ができます。当院では、こうした検査結果の意味づけを、遺伝カウンセリングを通じて、臨床遺伝専門医がていねいにお伝えしています。
一方で、注意しておきたいこともあります。パンゲノムを構築するアルゴリズムやグラフ理論そのものは、あくまで研究・技術基盤の話題であり、日常の臨床検査にそのまま置き換わるものではありません。臨床の現場でこれらの恩恵が広く行き渡るには、まだ時間と検証が必要です。現時点では「これから精度を底上げしていく土台が整いつつある段階」として理解しておくのが適切です。
8. 倫理とこれから:誰もが公平に恩恵を受けるために
パンゲノムが本当に「すべての人類」のためのものになるには、技術だけでなく、倫理的・法的・社会的な配慮(ELSI)が欠かせません。過去のゲノム研究には、特定のコミュニティから一方的にデータを取り出すような反省すべき事例もありました。HPRCはその教訓をふまえ、研究のあらゆる段階に倫理の専門家を組み込み、参加者が目的やリスクを十分に理解できるよう、難しい専門用語を平易な言葉に置き換えた透明性の高い同意プロセスを構築しています[14]。
もう1つ大切なのが、集団をどう記述するかという問題です。「アジア人」「アフリカ人」といった大陸レベルの大まかなラベルは、内部の多様性を覆い隠してしまい、時に誤解や差別につながります。HPRCは、こうした大まかなラベルの安易な使用を避け、科学的に適切な集団記述子を用いるベストプラクティスに沿うことを研究コミュニティに求めています。さらに、既存の細胞株だけに頼らず、新たなコホートから前向きに参加者を募る取り組みも進めており、多様性を「後付け」ではなく最初から設計に組み込もうとしています。
その中心にあるのが、2つの原則の両立です。1つは、データを見つけやすく・使いやすくする「FAIR原則」。もう1つは、データを提供したコミュニティに利益が還元され、その権利と管理が尊重されるようにする「CARE原則」です。データを開くだけでは、立場の弱い集団のデータが不適切に利用されるリスクを防げません。HPRCはこの2つを組み合わせることで、科学の発展と、多様な集団への尊厳・利益の還元を同時に実現しようとしています[14]。
日本の私たちにとっても、これは他人事ではありません。最初のドラフトに日本人のハプロタイプは含まれておらず、その後、日本人集団に固有の多様性を反映したパンゲノムグラフを独自に構築する研究も報告され始めています。世界の標準リファレンスが真に多様性を映すものになってはじめて、日本人を含むすべての集団が、公平で正確なゲノム医療の恩恵を受けられます。2026年に予定されるT2Tベースの完全なパンゲノムの完成は、その大きな転換点になると期待されています。
9. よくある誤解
誤解①「パンゲノムは1人の完璧なゲノムのこと」
パンゲノムは1人分の配列ではなく、多くの人のゲノムを分かれ道のあるグラフとして束ねたものです。1本の直線ではなく、多様な道を含む地図だという点が本質です。
誤解②「もう完成していて、すぐ検査に使える」
パンゲノムは段階的に拡大している途中です。研究面での成果は大きいものの、日常の臨床検査に広く行き渡るには、まだ検証と時間が必要な段階です。
誤解③「GRCh38はもう不要になる」
当面は、従来の座標系との橋渡しが重要です。多くのデータや知見がGRCh38を基準に蓄積されているため、パンゲノムはそれらと連携しながら役割を広げていきます。
誤解④「日本人には関係ない海外の話」
むしろ逆です。標準の地図が多様になるほど、これまで反映されにくかった日本人集団の多様性も正確に扱えるようになり、恩恵は世界中に広がります。
よくある質問(FAQ)
🏥 遺伝子検査・遺伝カウンセリングのご相談
保因者スクリーニングや出生前診断など
遺伝子検査・遺伝カウンセリングに関するご相談は
臨床遺伝専門医が在籍するミネルバクリニックへお気軽にどうぞ。
参考文献
- [1] The Need for a Human Pangenome Reference Sequence. PMC. [PMC8410644]
- [2] Human Pangenome Reference Consortium(公式サイト). [humanpangenome.org]
- [3] A draft human pangenome reference. Nature. 2023. [Nature]
- [4] Release Timeline. Human Pangenome Reference Consortium. [HPRC Release Timeline]
- [5] Telomere-to-telomere assembly of diploid chromosomes with Verkko. PMC. [PMC10427740]
- [6] Scalable telomere-to-telomere assembly for diploid and polyploid genomes with double graph. PMC. [PMC10274930]
- [7] Rapid, accurate long- and short-read mapping to large pangenome graphs with vg Giraffe. PMC. [PMC12621775]
- [8] Complete reference genome and pangenome improve genome-wide detection and interpretation of DNA methylation. PMC. [PMC12288590]
- [9] Multiscale analysis of pangenomes enables improved representation of genomic diversity. PMC. [PMC10406601]
- [10] Clinical SMN1 and SMN2 Gene-Specific Sequencing to Enhance the Clinical Sensitivity of Spinal Muscular Atrophy Diagnostic Testing. PMC. [PMC11919053]
- [11] Long-read sequencing identifies copy-specific markers of SMN gene conversion in spinal muscular atrophy. PMC. [PMC11927269]
- [12] Sequence Variation within the KIV-2 Copy Number Polymorphism of the Human LPA Gene in African, Asian, and European Populations. PMC. [PMC4378929]
- [13] Characterization of large-scale genomic differences in the first complete human genome. PMC. [PMC10320979]
- [14] HPRC Embedded ELSI(FAIR & CARE原則). Human Pangenome Reference Consortium. [HPRC Embedded ELSI]






