目次
遺伝暗号の基本となるコドン表の解説から、それがどのようにして生物のアミノ酸へと翻訳されるのかを明らかにします。高校生から研究者まで、遺伝学の基礎を網羅するこの記事で、生命の進化におけるコドンの重要性について学びましょう。
第1章 コドンとは
コドン表の基礎知識
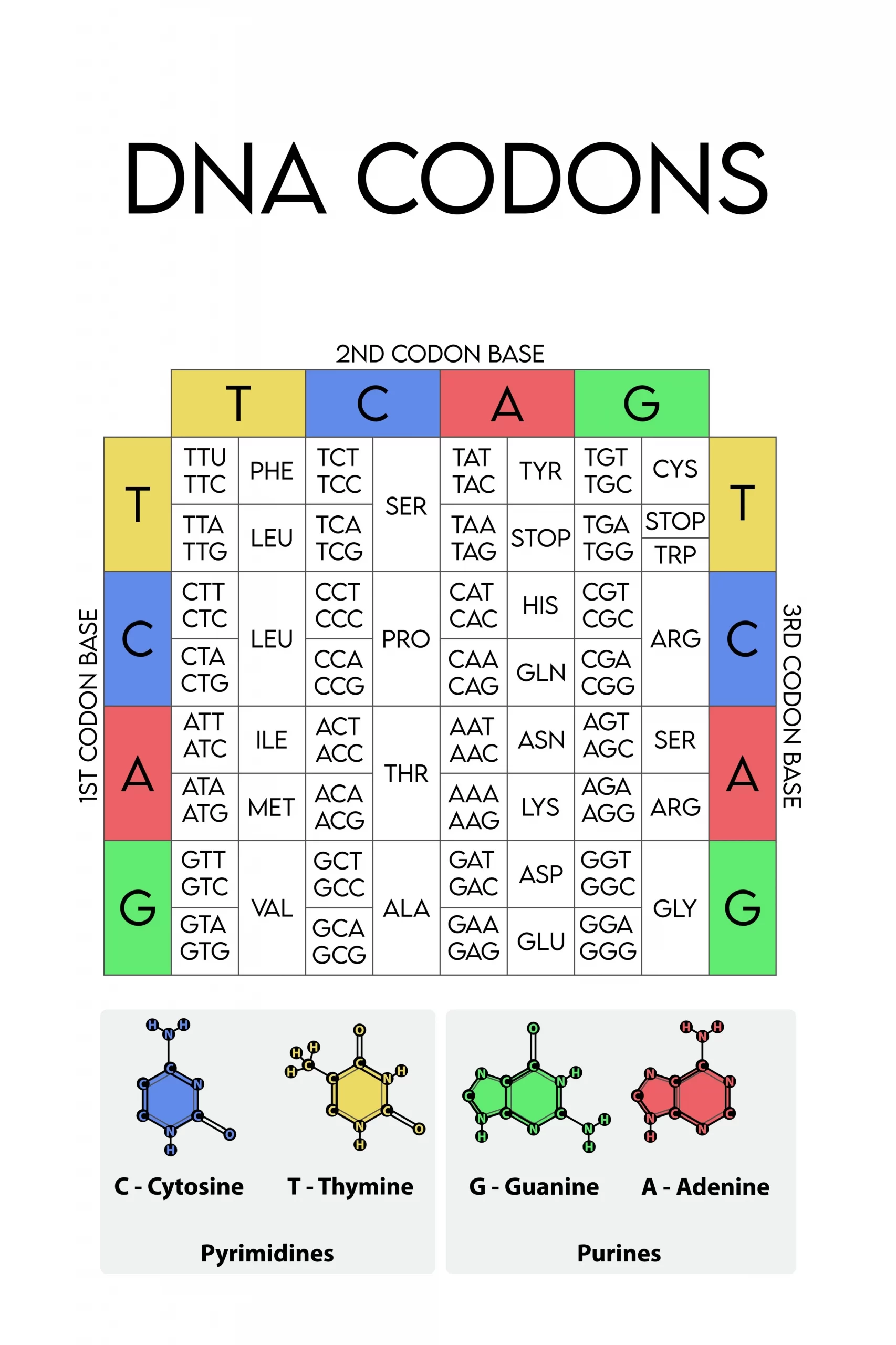
コドン表は、mRNAの塩基配列とそれが指定するアミノ酸との対応関係を示した表です。生物の遺伝情報はDNAに保存されており、タンパク質合成の過程でこの情報がmRNAに転写されます。mRNAの塩基配列は、3つの塩基が1組のコドンを形成し、それぞれのコドンが特定のアミノ酸を指定します[1][2][5]。
コドン表には64通りのコドンが存在し、これは4種類の塩基(アデニン(A)、ウラシル(U)、グアニン(G)、シトシン(C))が3つ組み合わさることで成り立っています。これらのコドンは20種類のアミノ酸に対応しており、1つのアミノ酸に対して複数のコドンが存在する場合もあります。例えば、フェニルアラニンはUUUとUUCの2つのコドンによって指定されます[6]。
コドン表には開始コドンと終止コドンも含まれています。開始コドンはAUGで、これはメチオニンを指定し、タンパク質合成の開始信号となります[2][5]。終止コドンはUAA、UAG、UGAの3つがあり、これらはアミノ酸を指定せず、タンパク質合成の終了を示します[5]。
コドンとアミノ酸の対応関係は、生物種によらず一定であるとされていますが、ヒトのミトコンドリア内では対応するアミノ酸の一部が異なる場合があります[5]。この普遍的なコドンとアミノ酸の対応関係は遺伝暗号と呼ばれ、生物学の基本的な概念の一つです。
コドン表は、mRNAの塩基配列からタンパク質のアミノ酸配列を予測する際に使用され、遺伝子の機能やタンパク質の構造を理解するための重要なツールです。また、遺伝子工学においては、特定のタンパク質を合成するために遺伝子を設計する際にも利用されます[6]。
- 参照・引用
-
[1] www.tenshi.or.jp/an-info/blogupload/EG3%E5%88%86%E5%AD%90%E9%81%BA%E4%BC%9D%E5%AD%A6%E3%81%AE%E5%9F%BA%E7%A4%8E%E7%9F%A5%E8%AD%98%EF%BC%88%E5%B7%AE%E6%9B%BF%E3%81%88%E7%89%88%EF%BC%89.pdf
[2] bio-sta.jp/beginner/proteinsynthesis/
[3] www.ieice-hbkb.org/files/S2/S2gun_06hen_02.pdf
[4] www.msdmanuals.com/ja-jp/home/01-%E7%9F%A5%E3%81%A3%E3%81%A6%E3%81%8A%E3%81%8D%E3%81%9F%E3%81%84%E5%9F%BA%E7%A4%8E%E7%9F%A5%E8%AD%98/%E9%81%BA%E4%BC%9D%E5%AD%A6/%E9%81%BA%E4%BC%9D%E5%AD%90%E3%81%A8%E6%9F%93%E8%89%B2%E4%BD%93
[5] ruo.mbl.co.jp/bio/product/epigenetics/article/gene-expression.html
[6] catalog.takara-bio.co.jp/product/basic_info.php?unitid=U100003628
遺伝暗号の役割と仕組み
遺伝暗号は、DNAに記録された遺伝情報をタンパク質のアミノ酸配列に変換するためのルールやコードです。この過程は、生物の形質や機能を決定する基本的なメカニズムであり、すべての生物に共通しています。
● 遺伝暗号の役割
遺伝暗号の主な役割は、DNAの塩基配列からタンパク質のアミノ酸配列への情報の翻訳です。DNAは、アデニン(A)、グアニン(G)、シトシン(C)、チミン(T)の4種類の塩基で構成されており、これらの塩基配列が遺伝情報をコードしています。一方、タンパク質は20種類のアミノ酸から構成されており、これらのアミノ酸の配列がタンパク質の機能や形状を決定します。遺伝暗号は、このDNAの塩基配列をアミノ酸配列に変換するためのルールを提供します。
● 遺伝暗号の仕組み
遺伝暗号は、3つの塩基からなる単位であるコドンによって表されます。各コドンは特定のアミノ酸を指定し、64種類のコドンが存在します。このうち61種類がアミノ酸をコードし、残りの3種類はタンパク質合成の終了を指示する終止コドンとして機能します。コドンとアミノ酸の対応関係は、遺伝暗号表にまとめられています。
遺伝暗号の翻訳プロセスは、主に以下のステップで構成されます:
1. 転写: DNAの塩基配列がメッセンジャーRNA(mRNA)に転写されます。この過程で、DNAのチミン(T)はmRNAのウラシル(U)に置き換えられます。
2. スプライシング: 真核生物では、mRNAの不要な部分(イントロン)が除去され、必要な部分(エキソン)が結合されます。
3. 翻訳: mRNAはリボソームによって読み取られ、tRNA(転移RNA)が持つアンチコドンとmRNAのコドンが対応することで、指定されたアミノ酸がペプチド鎖に組み込まれ、タンパク質が合成されます。
遺伝暗号は、その普遍性により、生物学の中心的な原理の一つとされています。すべての生物が基本的に同じ遺伝暗号を使用していることから、生命の共通の起源を示唆しています。また、遺伝暗号の研究は、遺伝子工学やバイオテクノロジーの分野での応用にもつながっています。
第2章 アミノ酸とコドンの関係
コドンによるアミノ酸の指定
コドンは、mRNA上に存在し、アミノ酸を指定する3つの塩基から構成されます。生物の遺伝情報はDNAに保存されており、この情報はRNAに転写された後、タンパク質へと翻訳されます。この過程で、コドンが重要な役割を果たします。コドンは、理論的には4×4×4=64通りの組み合わせが存在し、これらは20種類のアミノ酸に対応しています。しかし、1つのアミノ酸に対して複数のコドンが存在する場合があります。例えば、プロリンは4種類のコドンに指定されるアミノ酸です。このように、1つのアミノ酸に複数のコドンが対応する場合、3つ目の塩基が異なったとしても指定するアミノ酸は変わらないことが多いです。一方で、メチオニンやトリプトファンのように1つのアミノ酸に1つのコドンだけが対応する場合もあります。メチオニンはAUGというコドンにだけ、トリプトファンはUGGというコドンにだけ指定されるアミノ酸です[9][10]。
コドンとアミノ酸の対応関係は、遺伝暗号表にまとめられています。この表は、コドンに対応したアミノ酸を示しており、コドンの1番目の塩基を縦に、2番目の塩基を横に取り、コドンを構成する3つの塩基のすべての組み合わせが記されています。遺伝暗号表は、全ての生物で普遍的ではなく、例えばヒトのミトコンドリア内では対応するアミノ酸の一部が異なっています[14]。
遺伝暗号の研究は、1961年にニーレンバーグらによって始まり、彼らは大腸菌を破砕した抽出液にポリウリジン(U)を入れたところ、予想に反してポリフェニルアラニン(Phe)の合成が観察されました。これにより、ポリUがPheをコードすることが発見され、その後の研究によって全ての遺伝暗号が解読されました[14]。
開始コドンと終止コドンの特徴
開始コドンと終止コドンは、mRNA上でタンパク質の合成をそれぞれ開始と終了を指示する重要な役割を持つコドンです。これらは、遺伝情報の転写と翻訳の過程で中心的な役割を果たします。
● 開始コドン
開始コドンは、リボソームがmRNAに沿って動き、読み取った時にタンパク質合成を開始するコドンです。真核生物の核ゲノムの遺伝子に由来するmRNAでは、ほぼAUG(メチオニン)が開始コドンとして使われます。このAUGコドンは、遺伝子内部にも存在し、メチオニンのコドンとしても機能しますが、開始コドンとしての役割を果たすためには、その位置や文脈が重要です。開始コドンの指令にはAUG以外にも、まれにGUGが用いられることがあります[1][11]。
● 終止コドン
終止コドンは、タンパク質合成を終了させるために使われるコドンで、対応するアミノ酸(とtRNA)がないため、リボソームによる翻訳反応の完了を指示します。終止コドンにはUAA、UAG、UGAの3種類があり、これらはどのアミノ酸にも対応していません。終止コドンがmRNA上に出現すると、リボソームは翻訳を停止し、合成されたタンパク質はリボソームから離れていきます[2][10]。
● 共通点と相違点
開始コドンと終止コドンの共通点は、両者ともにタンパク質の合成過程において特定の段階(開始または終了)を指示する役割を持つことです。しかし、主な相違点は、開始コドンがタンパク質合成の開始を指示し、通常はメチオニン(AUG)またはまれにGUGがこの役割を果たすのに対し、終止コドンはタンパク質合成の終了を指示し、UAA、UAG、UGAの3種類がこの役割を果たす点です。また、開始コドンは特定のアミノ酸(メチオニン)に対応していますが、終止コドンはどのアミノ酸にも対応していないという違いがあります[1][2][10][11]。
- 参照・引用
-
[1] kotobank.jp/word/%E9%96%8B%E5%A7%8B%E3%82%B3%E3%83%89%E3%83%B3-1286266
[2] kotobank.jp/word/%E7%B5%82%E6%AD%A2%E3%82%B3%E3%83%89%E3%83%B3-1335750
[10] ja.wikipedia.org/wiki/%E7%B5%82%E6%AD%A2%E3%82%B3%E3%83%89%E3%83%B3
[11] ja.wikipedia.org/wiki/%E9%96%8B%E5%A7%8B%E3%82%B3%E3%83%89%E3%83%B3
第3章 遺伝子発現のプロセス
DNAからmRNAへの翻訳
DNAからmRNAへの翻訳という表現は、実際には生物学的なプロセスの誤解を招く可能性があります。正確には、DNAからmRNAへのプロセスは「転写」と呼ばれます。転写は、DNAの遺伝情報をmRNAにコピーする過程であり、その後に行われるmRNAからタンパク質への情報の変換は「翻訳」と呼ばれます。
● 転写のプロセス
転写は、細胞核内でDNAが持つ遺伝情報のうち、個々のタンパク質を合成するために必要な塩基配列をmRNAに写し取る過程です。このプロセスは、RNAポリメラーゼという酵素によって触媒されます。RNAポリメラーゼは、DNAの二重らせんをほどきながら、鋳型となる鎖の塩基の配列を読んで、これと相補的な塩基をもったヌクレオチドを次々と呼び込んで結合をつくっていきます[7][8][16][17][18][19][20]。
● 翻訳のプロセス
翻訳は、mRNAの塩基配列がタンパク質のアミノ酸配列に置き換えられる過程であり、「タンパク質の合成工場」とも呼ばれるリボソームで行われます。mRNAを移動するリボソームは、開始コドンを読み取ると、そこから翻訳を開始します。tRNAがアミノ酸を運び、リボソームはmRNAの塩基配列を解読しアミノ酸鎖を組み立て、特定の立体構造に折り畳まれて機能的なタンパク質を形成します[17][19].
したがって、DNAからmRNAへのプロセスは転写であり、mRNAからタンパク質へのプロセスは翻訳です。これらのプロセスは、遺伝情報がDNAからRNAを経てタンパク質へと流れるという概念を分子生物学ではセントラルドグマといいます[14].
- 参照・引用
-
[7] www.tmd.ac.jp/artsci/biol/pdf3/Chapt9.pdf
[8] www.tmd.ac.jp/artsci/biol/textintro/Chapt9.htm
[14] ruo.mbl.co.jp/bio/product/epigenetics/article/gene-expression.html
[15] www.vectorbuilder.jp/tool/dna-translation.html
[16] www.spring8.or.jp/ja/news_publications/research_highlights/no_14/
[17] www.try-it.jp/chapters-15090/sections-15091/lessons-15114/point-2/
[18] www.nig.ac.jp/museum/dataroom/translation/01_introduction/index.html
[19] www.nhk.or.jp/kokokoza/seibutsukiso/assets/memo/memo_0000008189.pdf
[20] www.ncc.go.jp/jp/ri/division/cancer_rna/20211227164725.html
遺伝子調節とコドンの使用
開始コドンと終止コドンの覚え方には、いくつかの方法がありますが、特に覚えやすいゴロ合わせが提案されています。開始コドンは、タンパク質の合成を開始する信号として機能し、終止コドンはタンパク質の合成を終了する信号として働きます。
開始コドンはAUGで、これはメチオニンをコードします。終止コドンにはUAA、UAG、UGAの3つがあり、これらはどのアミノ酸もコードしません。
覚え方の一例として、以下のゴロ合わせがあります:
– 開始コドン(AUG)の覚え方:「8月(AUG)から始める」。このゴロ合わせは、AUGが8月を意味する英語の略称と同じであることから来ています。また、AUGがメチオニンをコードする開始コドンであることを示しています[2]。
– 終止コドン(UAA、UAG、UGA)の覚え方:「うああ(UAA)」「うあぐ(UAG)」「うがあ(UGA)」で終わる。このフレーズは、終止コドンの3つの配列を覚えるのに役立ちます。特に、「うああ」「うあぐ」「うがあ」という音は、それぞれのコドンの配列と響きが似ており、覚えやすくなっています[2]。
これらのゴロ合わせは、開始コドンと終止コドンを覚える際に役立ち、特に生物学や分子生物学を学ぶ学生にとって有用なツールとなります。
第4章 コドンの多様性と生物進化
コドンの多様性とその進化的意義
DNAからmRNAへの翻訳という表現には誤りがあります。正しくは、DNAからmRNAへの**転写**です。転写とは、DNAの遺伝情報をRNAに写し取る過程のことを指します。具体的には、DNAの二重らせん構造のうち、一方の鎖(テンプレート鎖)の塩基配列に基づいて、相補的なRNA鎖が合成されます。この過程は、RNAポリメラーゼという酵素によって触媒されます[1][2][3][5][6][7][8][9][10][11][12][13][14][15][16][17][18][19][20]。
DNAからmRNAへの転写は、遺伝子発現の最初の段階として重要であり、遺伝子が働き始めるための基礎を築きます。RNAポリメラーゼは、DNAのプロモーター領域に結合し、DNAをほどきながら、テンプレート鎖の塩基配列を読み取り、相補的なRNA鎖を合成します[4][13]。この過程で生成されるRNAは、pre-mRNAと呼ばれ、さらに成熟mRNAへと加工されます。成熟mRNAは、イントロンと呼ばれる不要な塩基配列が除去され、エキソンと呼ばれるタンパク質設計に必要な部分が結合されることで完成します[11][19]。
成熟したmRNAは、核から細胞質へと移動し、リボソームでの翻訳の過程を経て、タンパク質へと変換されます。翻訳とは、mRNAの塩基配列がアミノ酸の配列に置き換えられる過程であり、タンパク質の合成が行われます[14][15][16]。この過程では、mRNA上のコドン(3つの塩基からなる単位)が、それぞれ特定のアミノ酸を指定し、tRNA(トランスファーRNA)が運ぶアミノ酸をリボソーム上で結合させることにより、タンパク質が合成されます[14][15][16]。
したがって、DNAからmRNAへの過程は転写であり、その後のmRNAからタンパク質への過程は翻訳と呼ばれます。これらの過程を通じて、DNAに記録された遺伝情報がタンパク質という実行形式へと変換され、生物の形質や機能が実現されます。
- 参照・引用
-
[1] www.sc.fukuoka-u.ac.jp/~bc1/Biochem/transcrp.htm
[2] bsw3.naist.jp/ko-kato/res-transcription.html
[3] bio-sta.jp/beginner/proteinsynthesis/
[4] www.spring8.or.jp/pdf/ja/SP8_news/no14_04/p2-p4.pdf
[5] www.tmd.ac.jp/artsci/biol/pdf3/Chapt9.pdf
[6] www.tmd.ac.jp/artsci/biol/textintro/Chapt9.htm
[7] www.amed.go.jp/news/release_20200418.html
[8] jsv.umin.jp/microbiology/main_006.htm
[9] www.thermofisher.com/us/en/home/life-science/pcr/real-time-pcr/real-time-pcr-learning-center/gene-expression-analysis-real-time-pcr-information/introduction-gene-expression.html
[10] www.tmd.ac.jp/artsci/biol/pdf/geneteng.pdf
[11] ruo.mbl.co.jp/bio/product/epigenetics/article/gene-expression.html
[12] www.vectorbuilder.jp/tool/dna-translation.html
[13] www.spring8.or.jp/ja/news_publications/research_highlights/no_14/
[14] www.try-it.jp/chapters-15090/sections-15091/lessons-15114/point-2/
[15] www.nig.ac.jp/museum/dataroom/translation/01_introduction/index.html
[16] www.nhk.or.jp/kokokoza/seibutsukiso/assets/memo/memo_0000008189.pdf
[17] www.nig.ac.jp/museum/genetic05.html
[18] www.try-it.jp/chapters-10394/sections-10395/lessons-10425/
[19] www.ncc.go.jp/jp/ri/division/cancer_rna/20211227164725.html
[20] www.jstage.jst.go.jp/article/tits/26/10/26_10_38/_pdf
異なる生物種におけるコドン使用の違い
遺伝子の調節とコドンの使用は、生物の遺伝情報の発現において重要な役割を果たします。遺伝子の調節は、特定の遺伝子がいつ、どのように、どれだけの量で発現するかを決定するプロセスです。一方、コドンの使用は、mRNAの翻訳過程において、どのアミノ酸がタンパク質の特定の位置に組み込まれるかを決定する役割を持ちます。
● 遺伝子の調節
遺伝子の調節は、転写因子、プロモーター領域、エンハンサー領域、サイレンサー領域など、多くの要素によって行われます。転写因子は、特定のDNA配列に結合し、その遺伝子の転写を促進または抑制するタンパク質です。プロモーター領域は、RNAポリメラーゼがDNAに結合し、転写を開始する場所を指定します。エンハンサー領域とサイレンサー領域は、遺伝子の転写レベルをそれぞれ上昇させたり、下降させたりする役割を持ちます。
● コドンの使用
コドンは、mRNA上の3つのヌクレオチドの配列であり、特定のアミノ酸または翻訳終了信号を指定します。生物種によって、特定のアミノ酸に対して好まれるコドン(コドンバイアス)が存在します。コドンバイアスは、翻訳の効率や精度に影響を与えることが知られています。例えば、あるコドンが細胞内で豊富に存在するtRNAによって認識される場合、そのコドンは効率的に翻訳されます。
● 遺伝子調節とコドン使用の関係
遺伝子の調節とコドンの使用は、タンパク質の発現レベルと活性を最適化するために相互に作用します。例えば、遺伝子工学においては、異種宿主での高いタンパク質発現を達成するために、コドンの最適化が行われることがあります。これは、宿主のコドンバイアスに合わせて、遺伝子のコドン配列を変更することによって、翻訳効率を向上させることを目的としています。
遺伝子の調節とコドンの使用は、生物の遺伝情報の発現における複雑な相互作用の一部を形成しており、生物の適応や進化において重要な役割を果たしています。
第5章 コドン表の使い方
高校生向け:コドン表の読み方と授業への応用
コドン表は、mRNAの塩基配列とそれに対応するアミノ酸との関係を示した表です。mRNAの塩基配列は、アデニン(A)、ウラシル(U)、グアニン(G)、シトシン(C)の4種類の塩基で構成され、3つの塩基が一組となってコドンを形成します。コドンは、タンパク質を構成するアミノ酸を指定する役割を持ちます。コドン表を読む際には、以下の手順を踏みます[15]。
1. コドンの特定: mRNAの塩基配列を3つずつ区切り、それぞれのコドンを特定します。
2. コドン表の使用: コドン表を使って、各コドンが指定するアミノ酸を見つけます。コドン表では、コドンの最初の2つの塩基で行と列を決定し、3番目の塩基で特定のアミノ酸を見つけます。
3. アミノ酸の連結: コドンに対応するアミノ酸を順に連結させ、タンパク質のアミノ酸配列を形成します。
● 授業への応用
コドン表の読み方を理解した上で、以下のように授業に応用することができます。
– 理解の確認: 生徒にコドン表を使って特定のmRNAの塩基配列からアミノ酸配列を導き出させることで、遺伝暗号の理解度を確認します。
– 実践的な演習: 実際の遺伝子の塩基配列を例に取り、生徒にタンパク質のアミノ酸配列を予測させます。
– 突然変異の影響の理解: 突然変異によってコドンが変化した場合のアミノ酸配列の変化を分析させ、突然変異がタンパク質の機能に与える影響を理解させます。
– 遺伝暗号の普遍性と例外: 普遍的な遺伝暗号表と、特定の生物で見られる遺伝暗号の例外(例えばミトコンドリアの遺伝暗号)について学び、遺伝暗号の進化について考察させます[17]。
コドン表の読み方を授業で扱うことは、生徒が遺伝の基本的な概念を理解し、生命科学の基礎を学ぶ上で非常に重要です。また、生徒が実際にコドン表を使ってアミノ酸配列を導き出すことで、遺伝情報の読み取りとタンパク質合成のプロセスをより深く理解することができます。
研究者向け:コドン使用の解析と科学的課題
コドン使用の解析は、遺伝子発現の効率性、遺伝子の進化、およびタンパク質の構造と機能に関する理解を深めるための重要な手段です。コドンは、mRNA上の3つの連続したヌクレオチドであり、特定のアミノ酸を指定します。生物種や組織、さらには個々の遺伝子レベルでコドン使用には顕著なバリエーションが存在し、これらのパターンを解析することで、生物学的プロセスの微妙な調節メカニズムを明らかにすることができます。
● コドン使用のバイアス
コドン使用のバイアスは、特定のアミノ酸に対して、利用可能な複数のコドンの中から一部が選好的に使用される現象です。このバイアスは、遺伝子発現の効率、mRNAの安定性、タンパク質の折りたたみに影響を及ぼす可能性があります。例えば、高い発現を示す遺伝子では、効率的な翻訳を促進するコドンが選択されることが多いです。一方で、コドン使用のバイアスは、遺伝子の進化的適応や種間の遺伝的多様性にも関連しています。
● コドン使用の解析手法
コドン使用の解析には、いくつかの計算手法があります。最も一般的なのは、コドン適応指数(CAI)や相対的合成効率(RSCU)など、コドン使用のバイアスを定量化する指標を用いる方法です。これらの指標は、特定の遺伝子やゲノム全体のコドン使用パターンを評価し、他の生物種や条件と比較するために使用されます。また、機械学習やクラスタリングといったデータ解析技術を用いて、大規模なゲノムデータセットからコドン使用のパターンを抽出する研究も行われています。
● 科学的課題
コドン使用の解析は、いくつかの科学的課題に直面しています。まず、コドン使用のバイアスが生物学的にどのような意味を持つのか、そのメカニズムを完全に理解することが挑戦的です。また、異なる生物種や環境条件下でのコドン使用の変動を正確に解析し、その進化的意義を解明することも重要な課題です。さらに、コドン使用のバイアスがタンパク質の構造や機能に与える影響を詳細に調べることも、今後の研究で解決すべき問題の一つです。
● 結論
コドン使用の解析は、分子生物学、進化生物学、およびシステム生物学の分野において重要な研究ツールです。この分野の進展は、生命の基本的なメカニズムを理解する上で貴重な洞察を提供し、遺伝子工学や合成生物学の応用においても重要な意味を持ちます。今後、新しい計算手法や実験技術の開発により、コドン使用の解析はさらに進化し、生物学的な謎の解明に貢献していくことが期待されます。








